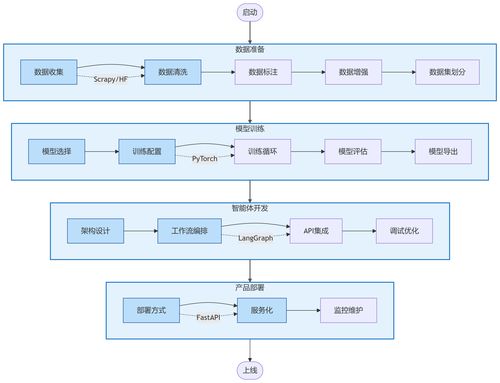
AI產品開發是一個系統化的過程,涉及多個關鍵環節。以下是從數據準備到產品部署的完整流程指南:
一、數據準備階段
- 數據需求分析:明確產品目標,確定所需數據類型(圖像、文本、音頻等)。
- 數據采集:通過公開數據集、爬蟲技術或人工標注等方式收集原始數據。
- 數據清洗與預處理:包括去除噪聲數據、處理缺失值、數據歸一化等。
- 數據標注:對數據進行人工或半自動標注,為模型訓練提供監督信號。
- 數據增強:通過旋轉、裁剪、加噪聲等技術擴充數據集,提升模型泛化能力。
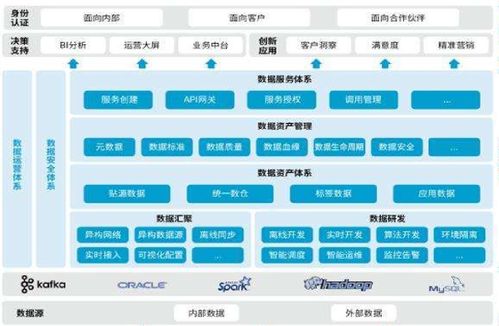
二、數據處理與特征工程
- 特征提取:從原始數據中提取有意義的特征(如文本的TF-IDF、圖像的HOG特征)。
- 特征選擇:使用相關性分析、主成分分析等方法篩選重要特征。
- 數據分割:將數據集劃分為訓練集、驗證集和測試集,通常比例為6:2:2。
三、模型開發與訓練
- 模型選擇:根據任務類型選擇合適的算法(如CNN用于圖像分類,Transformer用于NLP)。
- 模型訓練:使用訓練數據迭代優化模型參數。
- 模型驗證:在驗證集上評估模型性能,調整超參數。
- 模型測試:在測試集上進行最終性能評估。
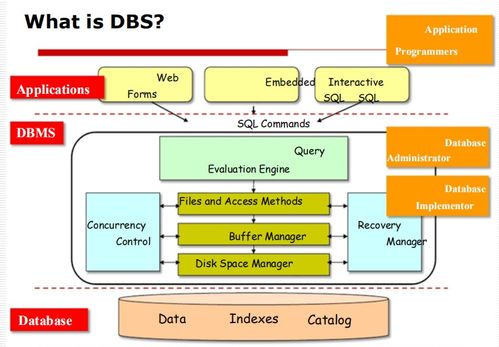
四、產品集成與部署
- 模型優化:進行模型壓縮、量化等操作,提升推理效率。
- API開發:將模型封裝為RESTful API或gRPC接口。
- 系統集成:將AI模塊集成到現有產品架構中。
- 部署上線:使用Docker容器化技術,部署到云服務器或邊緣設備。
五、運維與迭代
- 性能監控:實時監控模型推理準確率和響應時間。
- 數據回流:收集用戶反饋數據,用于模型迭代優化。
- A/B測試:對比不同版本模型的實際效果。
- 持續迭代:基于監控數據和用戶反饋,定期更新模型版本。
在整個流程中,數據處理是最基礎和關鍵的環節。高質量的數據是AI產品成功的基石,需要投入足夠資源和精力。同時,模型部署后的持續優化和迭代也是確保產品長期競爭力的重要保障。