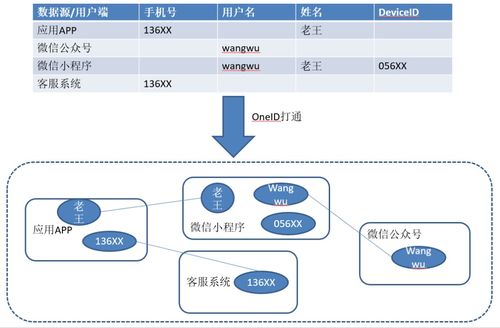
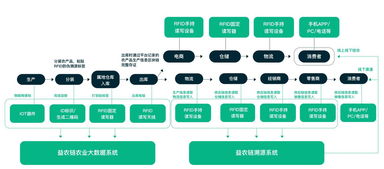
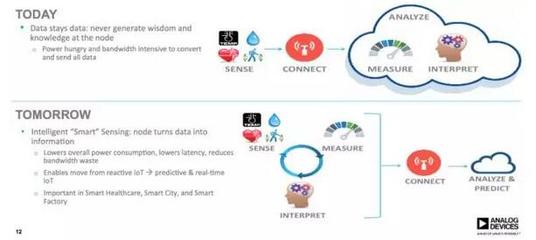
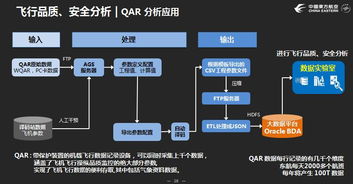
技術交底書是保障技術方案準確、高效實施的關鍵文檔,對于數據處理這類邏輯復雜、細節繁多的領域尤為重要。一份高質量的數據處理技術交底書,不僅是開發與執行團隊之間的溝通橋梁,也是項目可追溯、可復現的重要保障。本文將系統闡述撰寫高質量數據處理技術交底書的核心要素與具體方法。
一、明確交底書的核心目標與受眾
在動筆之前,需明確文檔的根本目標:確保接收方能夠清晰、完整、無誤地理解數據處理的需求、邏輯、步驟及注意事項,并能獨立正確執行。需明確受眾是誰——是數據工程師、算法研究員、業務分析師還是運維人員?針對不同受眾,技術深度、業務背景說明的詳略應有所調整。
二、結構化內容框架:六大核心模塊
一份完整的數據處理技術交底書通常應包含以下模塊:
- 項目概述與目標
- 項目背景:簡要說明為何要進行此數據處理,解決什么業務或技術問題。
- 處理目標:清晰定義本次數據處理的最終輸出物是什么(例如:一張清洗后的用戶行為表、一個特征數據集、一份聚合統計報告),以及需要滿足的質量標準(如準確性、完整性、時效性要求)。
- 范圍與邊界:明確說明處理的數據范圍(時間范圍、數據主體范圍等)以及不做處理的例外情況。
- 數據源說明
- 輸入數據詳述:列出所有輸入數據源,包括但不限于:
- 數據表/文件名稱、位置(庫、表、路徑、接口URL)。
- 關鍵字段清單、數據類型、含義(提供數據字典或樣例)。
- 數據更新頻率、增量/全量標識。
- 數據質量現狀(已知的臟數據、缺失、異常情況)。
- 依賴關系:說明是否存在上游依賴,其就緒條件或觸發時機。
- 數據處理邏輯與流程
- 總體流程圖:使用流程圖(如UML活動圖、簡單的方框圖)直觀展示處理的整體步驟與分支。
- 分步詳細邏輯:這是交底書的核心。對流程圖中每一步進行細化說明:
- 步驟編號與名稱。
- 操作描述:具體做什么(如:關聯、過濾、聚合、計算新字段、格式轉換)。
- 邏輯規則:用公式、偽代碼或嚴謹的自然語言描述業務規則與計算邏輯。例如:“
用戶等級 = IF(累計消費金額 >= 1000, 'VIP', IF(累計消費金額 >= 500, '高級', '普通'))”。
- 輸入與輸出:明確本步的輸入數據與產出中間數據。
- 核心算法/模型說明:若涉及復雜算法或機器學習模型,需說明其原理、關鍵參數、版本及輸入輸出格式。
- 輸出結果規范
- 輸出物定義:詳細描述最終輸出數據的:
- 存儲位置與格式(如:Hive表
dw.user<em>profile</em>final,Parquet格式)。
- 表結構(字段名、類型、注釋,特別是新增或含義變更的字段)。
- 數據分區方式(如按
dt日期分區)。
- 數據質量校驗規則:提供用于驗證輸出數據是否正確的SQL檢查語句或質量指標(如:記錄數波動范圍、關鍵字段非空率、值域范圍、與歷史數據的一致性對比方法)。
- 異常處理與容錯機制
- 常見異常場景:預判可能出現的錯誤(如:數據源缺失、數據格式異常、計算溢出、關聯鍵丟失)。
- 處理預案:針對每種異常,明確處理方式(如:告警并中止、使用默認值填充、記錄至異常日志表供人工排查)。
- 重跑與回滾方案:說明任務失敗后如何重新處理,以及如何撤銷錯誤輸出。
- 環境、資源與執行說明
- 運行環境:指明所需的計算環境(如:Spark集群版本、Python環境及依賴包列表)。
- 調度與依賴:說明任務調度方式(如:Airflow DAG ID、Crontab表達式)、上游依賴任務。
- 性能與資源預估:對關鍵步驟的數據量、處理耗時、所需內存/CPU進行預估,幫助執行方配置資源。
- 操作指令:提供可復現的、清晰的執行命令或腳本入口,并注明關鍵參數。
三、撰寫原則與技巧
- 清晰準確,無歧義:避免使用“大概”、“可能”等模糊詞匯,技術術語定義清晰。
- 圖文并茂,層級分明:多用流程圖、示意圖、表格和列表,結構使用標題層級清晰分隔。
- 實例化說明:對于復雜邏輯,提供輸入輸出的具體數據樣例,直觀演示轉換過程。
- 版本管理:文檔自身應有版本號和修訂歷史,記錄每次變更的內容、原因及日期。
- 可測試性:文檔描述的邏輯應具備可驗證性,最好能提供小規模測試用例或驗證查詢。
四、評審與維護
初稿完成后,應組織相關方(如需求方、開發、測試、運維)進行評審,根據反饋查漏補缺。數據處理邏輯變更時,技術交底書必須同步更新,確保其始終是當前處理方案的唯一權威描述。
撰寫高質量的數據處理技術交底書是一項需要嚴謹與細致的工作。它不僅是任務的說明書,更是團隊知識沉淀和傳承的載體。投入時間打造一份結構清晰、內容完備、描述精準的交底書,將極大地降低溝通成本、提升處理準確率與團隊協作效率,為數據產出的可靠性與價值實現奠定堅實基礎。